Aug. 14, 2019
一块自留地
放假之后一直在断断续续地学习。618图灵优惠的时候买了好几本书(电子书),目前只看完了《深入理解Python特性》,还是当天看完的,实体书应该也只是一本小册子吧……
一方面是因为我的Kindle,钢化膜+保护壳依然没有逃脱坏屏的悲剧,而换个屏幕跟二手差不多贵。说实话Kindle确实能帮我这种懒得出门买书的人阅读的。(拿着Kindle听音乐躺沙发上看书简直是入眠神技)
More...
放假之后一直在断断续续地学习。618图灵优惠的时候买了好几本书(电子书),目前只看完了《深入理解Python特性》,还是当天看完的,实体书应该也只是一本小册子吧……
一方面是因为我的Kindle,钢化膜+保护壳依然没有逃脱坏屏的悲剧,而换个屏幕跟二手差不多贵。说实话Kindle确实能帮我这种懒得出门买书的人阅读的。(拿着Kindle听音乐躺沙发上看书简直是入眠神技)
More...
准备换成《C++ Primer》了...
许多错误是在程序运行时发生的,要想程序更扎实,需要靠靠处理异常。
abort()使用abort()中断程序。
想了好久还是用这种方式水一水了。其实C++ Primer Plus并不适合有编程基础之后去读,不过懒得再找书了。学C++的过程中很尴尬的一点是实践机会不多,这样也能尽可能避免过目就忘的情况,权当笔记,会摘抄书中的一些代码。
More...
效果如图:
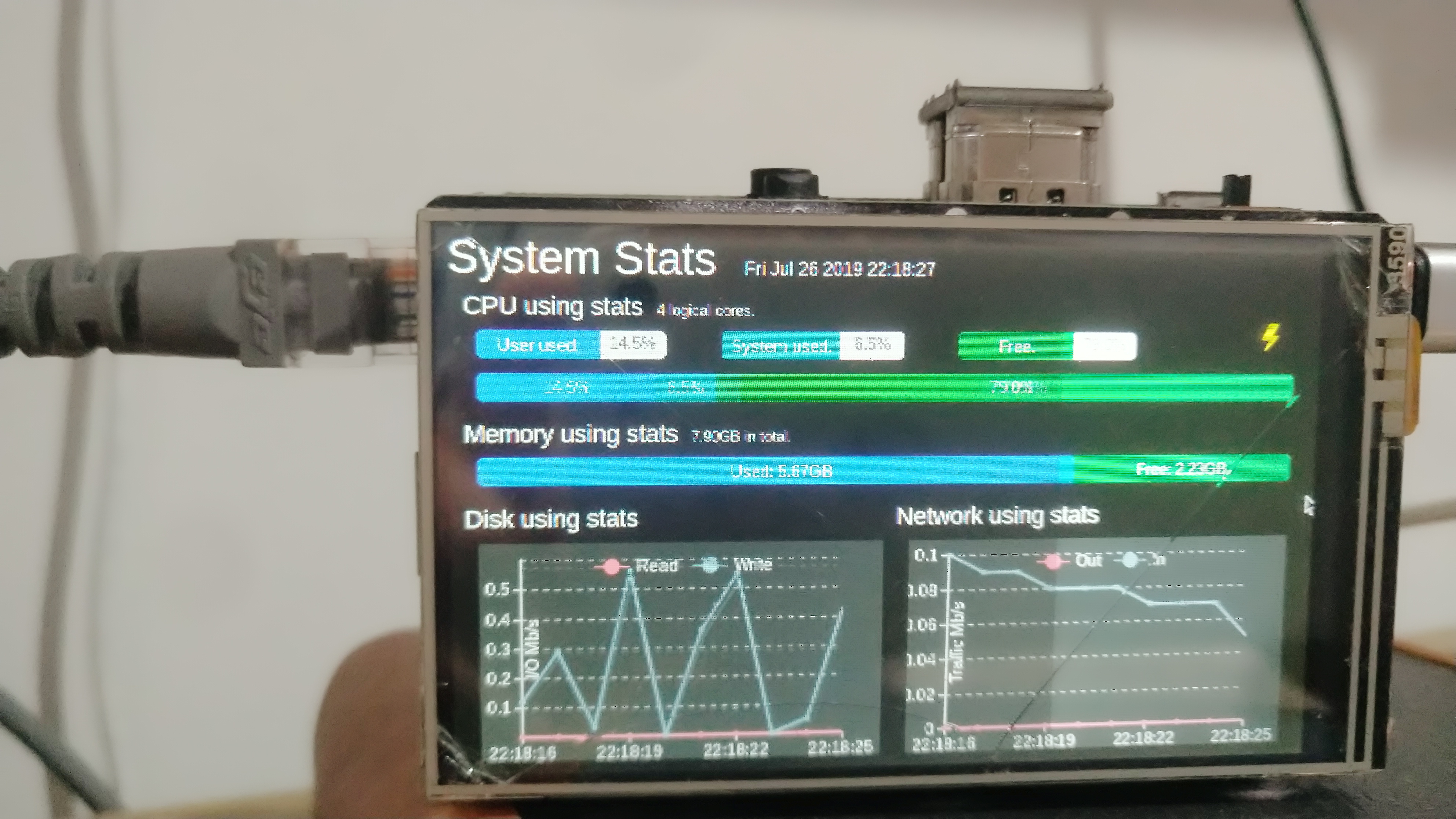
这是效果图:
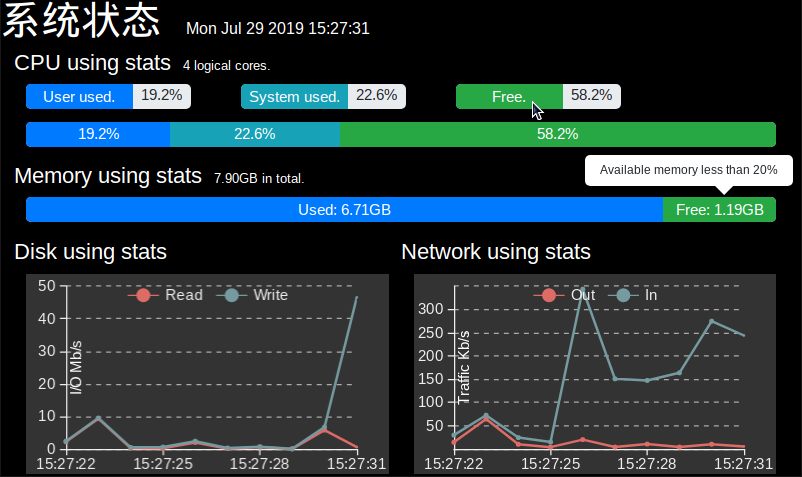
前端用js,后端用Python,实现还是比较简单的。
后端用psutil库获得电脑的各项信息然后用WebSocket发给前端,前端再处理到页面上。
前端用Bootstrap框架做出进度条来表示CPU和内存的占用百分比。缓存连续10次的数据,计算出硬盘和网络的流量速度,用echarts显示成折线图。
More...
Python3在处理一些底层应用时(比如socket编程)会用到字节类型(bytes)。
首先Python2与Python3的字节字符串大有不同,如果不幸看错了教程,那就悲剧了。以下内容均指Python3.
More...
如果觉得自己并不聪明到轻松理解技术书上的内容(尤其是译本),可以在读完一本进阶书籍后,练习一段时间,然后再找另一本相关的书或者其它权威的资料,再读,直至自己的理解与权威的说法一致,写出的代码足够Pythonic同时又不会滥用特性。
More...
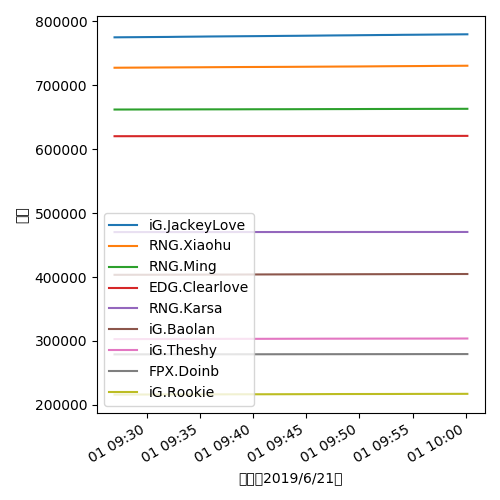
在使用Matplotlab绘制图表时,如果标签中包含中文,会显示初方块,这是因为默认的字体中没有包含中文。
可以在代码中手动指定字体:
import matplotlib.pyplot as plt plt.rcParams['font.sans-serif'] = ['STZhongsong']
STZhongsong(华文中宋)即是我们所指定的支持中文的字体。你可以使用自己喜欢的字体。
从今天开始才算是真正地完事了。去了一趟中传,去了一趟山师。
有时候会感觉很不是滋味,因为我原本以为能在最后一段时间多提升一些,结果发现三轮还没开始就结束了。再后悔也晚了,无论如何只是证明我的水平而已,没什么好说的。
More...
没有征兆,没有什么特别的地方。11:50左右上床睡觉,在床上躺了几十分钟后感觉到不对劲,毫无困意,一点也没有,熟悉的感觉不在了。
挣扎了三个小时后,现在是凌晨三点。我打开电脑,稍微有点头疼,感觉还好。也许是老天故意要给我一个写点什么东西的机会,否则我可能在很长一段时间之内都不会再打开WP了。
More...
用Python做了个Websocket的服务端,虽然知道相关的库应该早就有了,但是还是想自己做出来。
当然也参考了不少网上的教程,琢磨了好久的Websocket协议的格式。
内含一个WebsocketServer类,可以实现握手、建立连接、心跳(ping)、传输数据、上下文管理器。可以接收任意类型的数据,发送字符串(稍微改一下也可以发送二进制数据),支持数据分片(传输和发送都可以)。
More...