Python3在处理一些底层应用时(比如socket编程)会用到字节类型(bytes)。
首先Python2与Python3的字节字符串大有不同,如果不幸看错了教程,那就悲剧了。以下内容均指Python3.
声明一个字节类型的对象
我们可以用单引号或双引号的字面量表示法得到一个字符串类型:"Hello World"在字符串的字面量表示前加上b字母,就可以得到一个字节类型的对象。
bt = b"Hello World"因为我们只用了ASCII字符来创建字节类型,所以Python会自动将可读的部分按照转换为文字。如果数据是不可读的,则使用16进制来表示。
>> b"\x48" # 0x48是字母"H"对应的ASCII码 b"H" >> b"\x01\x02\x03" b'\x01\x02\x03'字符串的元素是字符,bytes对象的元素则是字节,我们可以用方括号来取得每个字节。本质上,字节对象就是一个整数数组
>> bt[0] 72得到的是一个0~255的数字(即8位二进制数字所能表示的十进制数字),我们知道,数据在计算机是用一串0和1来存储,每个0或1为一个比特(bit)又称"位",8个比特组成1个字节,即8bits=1byte。(这就是Mbps和MB/s差八倍的原因,前者是兆比特每秒,后者是兆字节每秒)
我们可以用bin(bt[0])来直观地表示每个字节在内存中的储存方式:
>> bin(bt[0]) '0b1001000'
除字面量表示之外,我们还可以用bytes()函数来得到字节类型,对于其他对象,需要实现bytes方法。
字节类型可以存储任意格式的数据,远远不限于文本,可以说图片、视频、音频等等,所以字节类型有更广阔的使用空间,是进行底层编程的不可或缺的工具。
字符串与字节类型的转换
解码与编码
字节类型转换为字符串类型的过程为解码,反之则是编码:>> bt.decode() # 将字节类型解码为字符串类型 'Hello World' >> s = 'Hello World' # 将字符串类型编码为字节类型 >> s.encode() b'Hello World'可以这样理解:数据以01的形式(机器码)存储在内存中,对人类来说是不可读的,所以要解码;反过来人类要把可读的文字存储到内存中,需要编码为计算机可以使用的数据。
decode() 和 encode()
decode() 函数有两个可选的参数: bytes.deocde(encoding="utf-8", errors="strict") ,encoding指编码,不指定则使用默认使用utf-8编码,error有三种取值:strict、ignore和replace,默认使用strict
- strict 对于任何无法被解码的字符都抛出错误
- ignore 忽略无法被解码的字符
- replace 替换无法被解码的字符
codecs.register_error(name, error_handler)有关,不再讨论)
很显然后两者都不是什么好办法,最好的方法是让它抛出错误,然后再检查数据是否存在问题。
encode()与前者相反,encode()将字符串编码为字节,参数与前者相同。 因为汉字或其他语言文字需要两到三个字节来存储,字节类型的字面量表示只支持ASCII字符:

>>> b = b"你好,世界" File "<input>", line 1 SyntaxError: bytes can only contain ASCII literal characters.所以我们需要
encode()来获得ASCII之外的字符(比如汉字)的字节类型:
>>> s = "你好,世界" >>> s.encode() b'\xe4\xbd\xa0\xe5\xa5\xbd\xef\xbc\x8c\xe4\xb8\x96\xe7\x95\x8c'
str()和bytes()
使用str()和bytes()函数同样可以实现二者的转换。
首先是str(),如果直接str(b),会出现下面的情况:
>>> str(b) "b'Hello World'" # 给出的是字面量形式
加上encoding关键字参数,让str()知道你是要解码字符串:
>>> str(b, encoding='utf-8') 'Hello world'
bytes()可将字符串类型转换为字节类型,实际上不仅是字符串,它可以将任意可迭代整数序列转化为字节类型,而字符串本质上也是整数数组(前面也说字节对象也是整数数组,从这里可以看出二者只是表示方式不同而已)。
>>> bytes("你好,世界", encoding="utf-8") # 使用字符串做参数时需要指定编码
b'\xe4\xbd\xa0\xe5\xa5\xbd\xef\xbc\x8c\xe4\xb8\x96\xe7\x95\x8c'
>>> bytes([1,2,3,5]) # 输入可迭代的整数序列
b'\x01\x02\x03\x05'
除bytes()之外,我们还会接触到struct类,它提供了更广泛的转换功能。
处理二进制数据
这里会举出两个例子,只是为了演示如何用字节类型处理二进制数据,所以你不需要知道它们究竟是做什么用的。构造Websockt帧
先举一个处理二进制数据的例子:Websocket帧。Websocket是用来网络通信的应用层协议,当然本文不需要知道Websocket是什么东西, 我们先来看如何构造一个Websocket帧.0 1 2 3 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 +-+-+-+-+-------+-+-------------+-------------------------------+ |F|R|R|R| opcode|M| Payload len | Extended payload length | |I|S|S|S| (4) |A| (7) | (16/64) | |N|V|V|V| |S| | (if payload len==126/127) | | |1|2|3| |K| | | +-+-+-+-+-------+-+-------------+ - - - - - - - - - - - - - - - + | Extended payload length continued, if payload len == 127 | + - - - - - - - - - - - - - - - +-------------------------------+ | |Masking-key, if MASK set to 1 | +-------------------------------+-------------------------------+ | Masking-key (continued) | Payload Data | +-------------------------------- - - - - - - - - - - - - - - - + : Payload Data continued ... : + - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - + | Payload Data continued ... | +---------------------------------------------------------------+阅读方法是一行一行看,前两行是标尺,单位是比特(位)。
每8比特(位)为一字节,第一个字节中,FIN占1位,3个RSV各占1位,opcode占4位。 假设我们要构造一个Websocket帧,以下是需求:
- 数据没有切片或者是最后一个切片,即
FIN置为1 - 三个
RSV用于协议扩展,我们用不到,全部置为0 - opcode指定帧类型
- 0x0:表示一个延续帧。当 Opcode 为 0 时,表示本次数据传输采用了数据分片,当前收到的数据帧为其中一个数据分片。
- %x1:表示这是一个文本帧(frame)
- %x2:表示这是一个二进制帧(frame)
- %x3-7:保留的操作代码,用于后续定义的非控制帧。
- %x8:表示连接断开。
- %x8:表示这是一个 ping 操作。
- %xA:表示这是一个 pong 操作。
- %xB-F:保留的操作代码,用于后续定义的控制帧。
假设我们用Websocket协议发送的数据是文本,即取
0x01。
FIN RSV OPCODE 1 000 0001连起来就是
10000001在Python中使用
0b前缀表示二进制字面量,得到对应的十进制数:
>>> 0b10000001 129反过来,我们可以将它解析出来,常用的是位运算:
>>> FIN = 129 % 0b10000000 >>> OPCODE = 129 & 0b00001111 >>> FIN, OPCODE (1, 1)如此,我们完成了一个二进制数据处理任务(的一部分)。
读取mp3的元数据
有关mp3格式的知识在这里可以找到: 先放好一会要用到的mp3文件。
首先读入文件:
# coding=utf-8
# ⬇使用二进制读入
f = open("想你的夜 - 关喆.mp3", 'rb')
用read()方法读入数据,该方法接受一个整数n,即读取前n个字节。我们先来尝试一下:
>>> f.read(3) b'ID3'
ID3表示采用ID3储存元数据。
mp3文件由3部分组成:
- ID3v2
- 音频数据部分
- ID3v1
# coding=utf-8输出:f = open(“想你的夜 - 关喆.mp3”, ‘rb’) header = f.read(10) for i in header: # hex将整数写成16进制的形式,这里只是为了更直观一些 print(hex(i), end=’ ‘)
0x49 0x44 0x33 0x3 0x0 0x0 0x0 0x21 0x6a 0x19
按照ID3v2.3头部的格式,我们可以将得到的前十个字节划分一下。
| 0x49 0x44 0x33 | 0x3 | 0x0 | 0x0 | 0x21 0x6a 0x19 |
|---|---|---|---|---|
| ID30x03 第三版 | 版本号 | 副版本号 | 标志字节 | 标签帧总长 |
表示标签帧总长度的一共四个字节,但每个字节只用7位,最高位不使用恒为0。如果要得到标签帧的大小,计算方法如下:
>>> bits = [0x0, 0x21, 0x6a, 0x19] # 表示标签帧总长度所用的4个字节 >>> length = (bits[0] << 21) + (bits[1] << 14) + (bits[2] << 7) + bits[3] # 注意这里 + 运算符的优先级大于 << >>> length 554265 # 标签帧总长度是554265字节
往下读length长度的文件,获得整个标签帧
# coding=utf-8
f = open("想你的夜 - 关喆.mp3", 'rb')
header = f.read(10)
length_bytes = header[-4:]
length = (length_bytes[0] << 21) + (length_bytes[1] << 14) + (length_bytes[2] << 7) + length_bytes[3]
tags = f.read(length)
>>> tags b'TSSE\x00\x00\x00\r\x00\x00\x00Lavf56.4.101COMM\x00\x00\x02\x07\x00\x00\x00XXX\x00163 key(Don\'t modify):L64FU3W4YxX3ZFTmbZ+8/UxuvnbxeU5+kDskFDcKcS6vslLeGLnaFpCv2iWyLFsFuKR1caPKvpZFjUI2yT0ncllGm4lpA04dlXdYL1HGcb7EM8q8FuTDpjFeN4gECi7UucXT+ZAkkJCYqDk5HDfQUBkbtlp0Mj5f4cI15pX+lUxHf8FjU5A84OixEHq8PIcV+tVJ4rhqUb9/KBTWwfFfFftTjW70YBn4ANFgTZRLbwW25HqBORa3IvWAdHre/uknrXnr7QPKEOICskFW/bD6Mw2NTcMD2lhOs5trtQ+rmgKOuVlY++LNWANV/L+3vTucorvDKhaSDIbtIm7y2TvaGWlNVVIRKSI7MyKhjwNFj9zXN+CK0TkzsI16qg8t+7+ofuMWhx0ggLph2Vubo6DjCVfTgKJ8ZzfO65ucUG/YUYXe9lz93ytmZ6bnUXw/RLwMYTKJADK30EzELw4B1AlLd3JJIfNcywkhnzzNfNQ+/N4=TALB\x00\x00\x00\r\x00\x00\x01\xff\xfe8l\xdc\x8f\x84v8l\xdc\x8fTIT2\x00\x00\x00\x0b\x00\x00\x01\xff\xfe\xf3``O\x84v\x1cYTPE1\x00\x00\x00\x07\x00\x00\x01\xff\xfesQ\x86UTPOS\x00\x00\x00\x05\x00\x00\x01\xff\xfe1\x00TRCK\x00\x00\x00\x05\x00\x00\x01\xff\xfe2\x00APIC\x00\x08n\x8c\x00\x00\x00image/jpeg\x00\x06\x00\x89PNG\r\n\x1a\n\x00\x00\x00\rIHDR\x00\x00\x02\x80\x00\x00\x02\x80\x08\x06\x00\x00\x00\x0c\xc...
ok,现在我们来把标签解析出来。一个标签帧由四部分组成:
0 1 2 3 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 +-------+-------+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+--------------- | Frame |Content|a|b|c|0|0|0|0|0|i|j|k|0|0|0|0|0| | spec..| length| | | | | | | | | | | | | | | | | Tag content... | 4 | 4 |1|1|1| | | | | |1|1|1| | | | | | +-------+-------+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+---------------
前四个字节是帧标识,说明一个帧的内容(Tag content)的含义,对应关系可以在前面给出的链接中找到。
>>> frame_spce = tags[0:4] # 取出第一个标签的帧 接下来4个字节是帧大小,计算方法与前面那个计算方法不同,这个是每个字节用8位,所以计算方法应该如下所示: ```python >>> bits = tags[4:8] # 表示第一个标签内容长度所用的4个字节 >>> length = (bits[0] << 24) + (bits[1] << 16) + (bits[2] << 8) + bits[3] # 注意这里 + 运算符的优先级大于 << >>> length 13 # 第一个标签内容的长度是13字节
接下来两字节是标志,在我给的链接里有说明,我们要获得的是标签内容,所以这里我们直接跳过它,从标签帧的第11(10 = 帧标识4bytes + 帧大小4bytes + 标志2bytes)(下标为10)个字节向下读13字节,得到第一个标签的内容。
>>> tags[10: 10 + 13] b'\x00Lavf56.4.101' # 标签内容附带一个空字节,这个空字节是算到长度中的,处理的时候去掉就行了
按这样的办法,我们可以写一个循环,用字典的形式把标签都读取出来。
# coding=utf-8
f = open("想你的夜 - 关喆.mp3", 'rb')
header = f.read(10)
length_bytes = header[-4:]
length = (length_bytes[0] << 21) \
+ (length_bytes[1] << 14) \
+ (length_bytes[2] << 7) \
+ length_bytes[3]
tags = {}
loaded = 0
while True:
k = f.read(4)
bits = f.read(4)
tag_len = (bits[0] << 24) + (bits[1] << 16) + (bits[2] << 8) + bits[3]
sign = f.read(2)
content = f.read(tag_len)
tags[k] = content
loaded += 4 + 4 + 2 + tag_len
if loaded >= length:
break
最后得到的tags
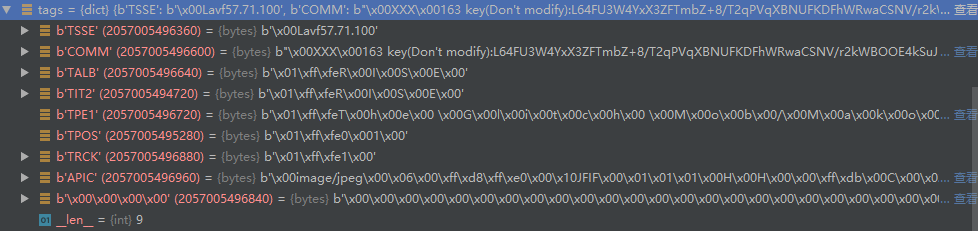
这个歌曲文件用的utf-16编码(有的使用的utf-8或者GB2312等等),我们将它解码出来:
title = tags['TIT2'][1:].decode('utf-16') # 第0位是一个标志位,所以从第1位往后取
author = tags['TPE1'][1:].decode('utf-16')
album = tags['TALB'][1:].decode('utf-16')
print(f"标题:{title}\n"
f"歌手:{author}\n"
f"专辑:{album}")
输出结果:
标题:想你的夜 歌手:关喆 专辑:永远的永远
我们得到的tags字典还包含了一个APIC,即歌曲的封面图片,可以看到里面有image/jpeg的字样表示图片的MIME类型。
然而~这个虽然标出的是jpeg文件,实际上存储的却是png,快把我坑死了。(如果是JPEG,可以找到JFIF字样)
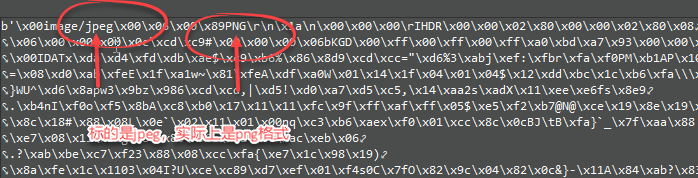
所以这个image/jpeg并不准确,我们还是按实际的来。查阅资料可知,应该从0x89处开始读取png格式的数据。
index = tags['APIC'].index(0x89)
image = tags['APIC'][index:]
# 然后将二进制数据写入到文件中,保存下来:
with open('cover.png', 'wb') as pic:
pic.write(image)
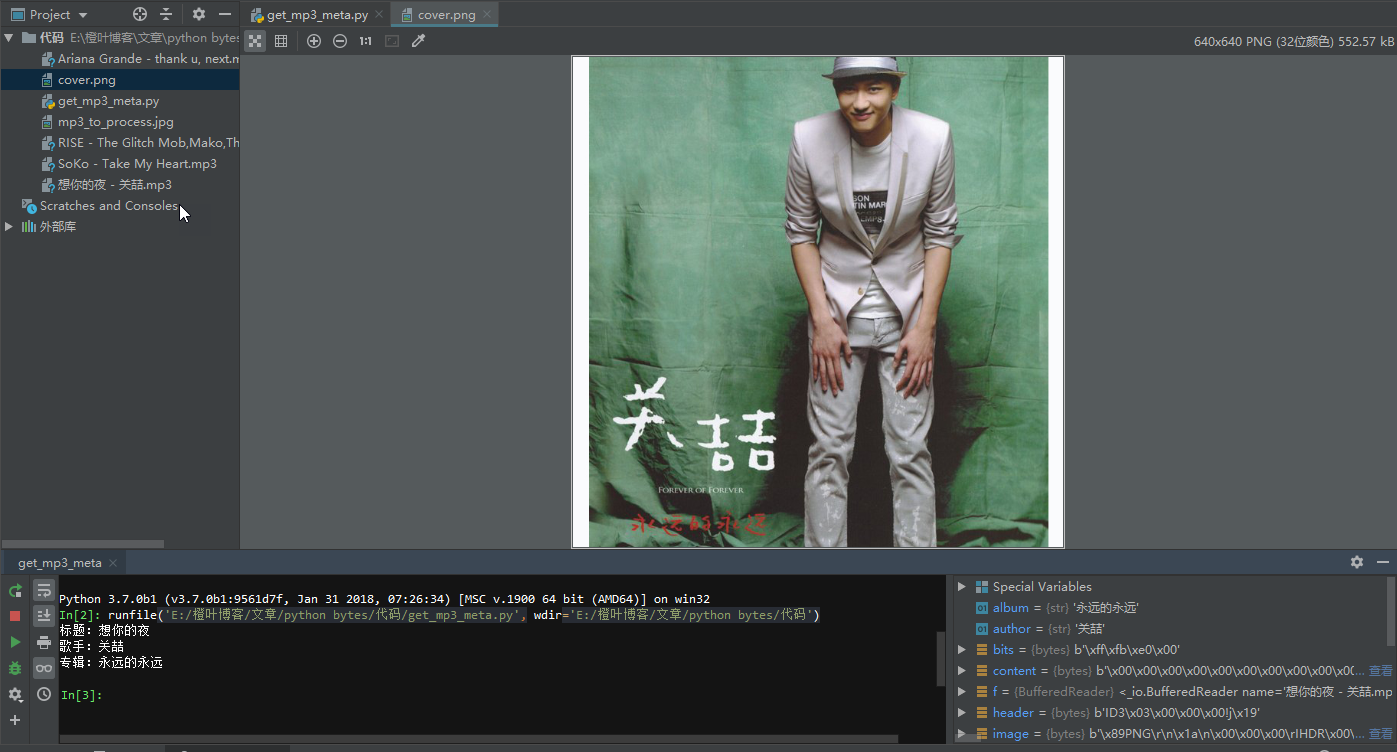
最终得到了歌曲的封面:
以下是完整的代码:
# coding=utf-8
f = open("想你的夜 - 关喆.mp3", 'rb')
header = f.read(10)
length_bytes = header[-4:]
length = (length_bytes[0] << 21) \
+ (length_bytes[1] << 14) \
+ (length_bytes[2] << 7) \
+ length_bytes[3]
tags = {}
loaded = 0
while True:
k = f.read(4)
bits = f.read(4)
tag_len = (bits[0] << 24) + (bits[1] << 16) + (bits[2] << 8) + bits[3]
sign = f.read(2)
content = f.read(tag_len)
tags[k.decode()] = content
loaded += 4 + 4 + 2 + tag_len
if loaded >= length:
break
title = tags['TIT2'][1:].decode('utf-16')
author = tags['TPE1'][1:].decode('utf-16')
album = tags['TALB'][1:].decode('utf-16')
print(f"标题:{title}\n"
f"歌手:{author}\n"
f"专辑:{album}")
index = tags['APIC'].index(0x89)
image = tags['APIC'][index:]
with open('cover.png', 'wb') as pic:
pic.write(image)
这样我们实现了简易的从歌曲文件中获取信息的功能,可以获取歌名、专辑名、歌手名和封面图片等等。Python已经提供了mutagen库来抽象化上述过程,如果你真的想制作一个读取音频文件(不仅是mp3)的工具,推荐使用mutagen来完成。
bytearray类型
字节类型是不可变的,而bytearray类型是可变的,创建一个bytesarray对象:bytearray(b'Hello, World')bytearray对象是可变的,可以像操作列表一样操作它:
In[18]: ba = bytearray(b'Hello World') In[19]: ba Out[19]: bytearray(b'Hello World') In[20]: ba.append(b'!'[0]) In[21]: ba Out[21]: bytearray(b'Hello World!')当你执行
a += b来拼接两个字节类型的对象时,实际上会重新创建一个新的字节对象再赋给a,对于次数较多的拼接,bytearray的效率更高。
