Aug. 5, 2019
想了好久还是用这种方式水一水了。其实C++ Primer Plus并不适合有编程基础之后去读,不过懒得再找书了。学C++的过程中很尴尬的一点是实践机会不多,这样也能尽可能避免过目就忘的情况,权当笔记,会摘抄书中的一些代码。
More...
Jul. 29, 2019
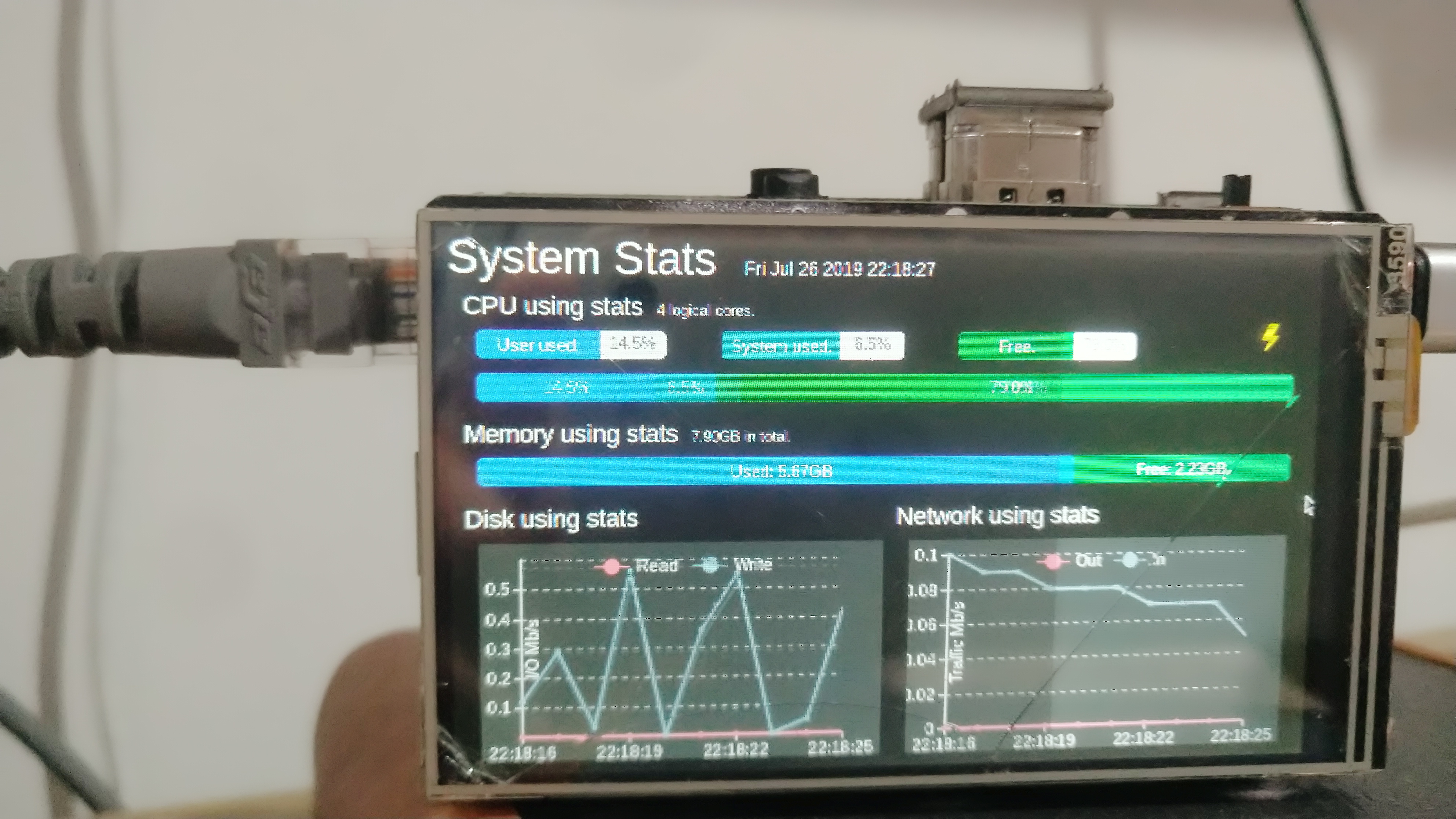
效果如图:

这是效果图:
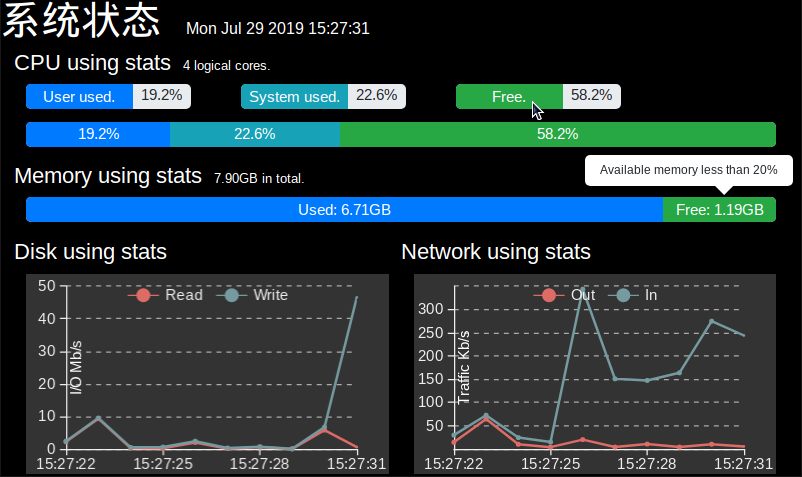
前端用js,后端用Python,实现还是比较简单的。
后端用psutil库获得电脑的各项信息然后用WebSocket发给前端,前端再处理到页面上。
前端用Bootstrap框架做出进度条来表示CPU和内存的占用百分比。缓存连续10次的数据,计算出硬盘和网络的流量速度,用echarts显示成折线图。
More...
Jul. 19, 2019
Python3在处理一些底层应用时(比如socket编程)会用到字节类型(bytes)。
首先Python2与Python3的字节字符串大有不同,如果不幸看错了教程,那就悲剧了。以下内容均指Python3.
More...
Jul. 8, 2019
如果觉得自己并不聪明到轻松理解技术书上的内容(尤其是译本),可以在读完一本进阶书籍后,练习一段时间,然后再找另一本相关的书或者其它权威的资料,再读,直至自己的理解与权威的说法一致,写出的代码足够Pythonic同时又不会滥用特性。
More...
Jun. 22, 2019
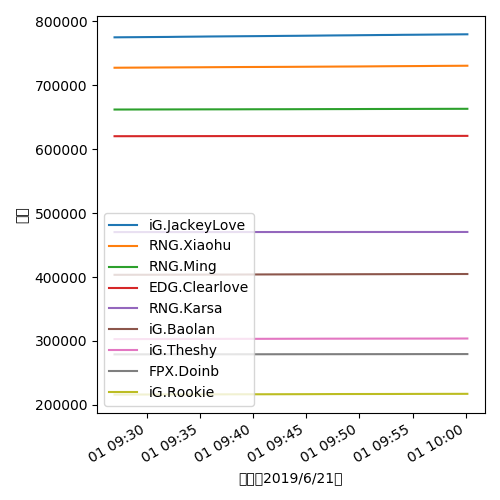
在使用Matplotlab绘制图表时,如果标签中包含中文,会显示初方块,这是因为默认的字体中没有包含中文。
可以在代码中手动指定字体:
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['STZhongsong']
STZhongsong(华文中宋)即是我们所指定的支持中文的字体。你可以使用自己喜欢的字体。
More...
Jun. 16, 2019
从今天开始才算是真正地完事了。去了一趟中传,去了一趟山师。
有时候会感觉很不是滋味,因为我原本以为能在最后一段时间多提升一些,结果发现三轮还没开始就结束了。再后悔也晚了,无论如何只是证明我的水平而已,没什么好说的。
More...
Mar. 21, 2019
没有征兆,没有什么特别的地方。11:50左右上床睡觉,在床上躺了几十分钟后感觉到不对劲,毫无困意,一点也没有,熟悉的感觉不在了。
挣扎了三个小时后,现在是凌晨三点。我打开电脑,稍微有点头疼,感觉还好。也许是老天故意要给我一个写点什么东西的机会,否则我可能在很长一段时间之内都不会再打开WP了。
More...
Mar. 16, 2019
用Python做了个Websocket的服务端,虽然知道相关的库应该早就有了,但是还是想自己做出来。
当然也参考了不少网上的教程,琢磨了好久的Websocket协议的格式。
内含一个WebsocketServer类,可以实现握手、建立连接、心跳(ping)、传输数据、上下文管理器。可以接收任意类型的数据,发送字符串(稍微改一下也可以发送二进制数据),支持数据分片(传输和发送都可以)。
More...
Feb. 10, 2019
后端的最后一部分。
-
- import json
- import re
-
-
- class Lyric2Book:
- support_format = ['txt', 'html']
- support_ts = ['parallel', 'chunk']
- html_template = """
- <section>
- <h2 class='header'>%(header)s</h2>
- <div class='info'>
- <div class='album'>%(album)s</div>
- <div class='artists'>%(artists)s</div>
- </div>
- <div class='content'>
- %(lyrics)s
- </div>
- </section>
- """
- html_frame = """<!DOCTYPE html>
- <html lang="zh-cn">
- <head>
- <meta charset="utf-8"/>
- <meta name="viewport" content="width=device-width, initial-scale=1" />
- <meta name="referrer" content="never" />
- <title>%s</title>
- </head>
- <body>
- %s
- </body>
- </html>
- """
- lyrics_template = "<div class='content-%(ver)d' >%(content)s</div>"
- txt_template = "%(header)s\n专辑:%(album)s\n作者:%(artists)s\n\n%(lyrics)s\n\n"
- txt_frame = "%s\n\n%s"
-
- def __init__(self, file_format='html', title='Lyrics', typesetting='parallel'):
- self.title = title
- if file_format in Lyric2Book.support_format:
- self.format = file_format
- else:
- raise Exception('Unsupported format: %s.' % file_format)
- self.res = ""
- self.data = ""
- if typesetting in Lyric2Book.support_ts:
- self.ts = typesetting
- else:
- raise Exception('Unsupported typesetting: %s' % typesetting)
-
- def chunk(self, lyrics):
- predlyric = []
-
- for item in lyrics:
- lines = []
- if item is not None:
-
- for line in item.split('\n'):
- line = re.sub('\(\d+,\d+\)', '', line)
- time_tag = ''.join(re.findall('\[.*?\]', line))
- line = [time_tag, line.strip(time_tag)]
- lines.append(line)
- predlyric.append(lines)
- output_section = ''
- if self.format == 'html':
- i = 1
- for item in predlyric:
- output_section += "<div class='content-%d'>\n" % i
- i += 1
- for line in item:
- output_section += "<p><span class='timetag'>%s</span>%s</p> \n" % (re.sub('[\[\]]', '-', line[0]), line[1])
- output_section += "</div>"
- elif self.format == 'txt':
- for item in predlyric:
- output_section += ""
- for line in item:
- format_tag = '-%s- ' % re.sub('[\[\]]', '-', line[0]) if line[0] else ''
- output_section += format_tag + line[1] + '\n'
- return output_section
-
- def parallel(self, lyrics):
- unpredlyric = []
- for item in lyrics:
- lines = {}
- if item is not None:
- for line in item.split('\n'):
- line = re.sub('\(\d+,\d+\)', '', line)
- time_tag = ''.join(re.findall('\[.*?\]', line))
- lines[time_tag] = line.strip(time_tag)
- unpredlyric.append(lines)
- predlyric = []
- for group_tag in list(unpredlyric[0].keys()):
- predlyric += [[group_tag] + [i.get(group_tag, unpredlyric[0][group_tag]) for i in unpredlyric]]
- dparallels = predlyric
- output_section = ''
- if self.format == 'html':
- for item in dparallels:
- output_section += "<div class='content'>\n"
- dtimetag = item[0]
- dcontent = item[1::]
- item_div = "<div class='timetag'>\n<p>{timetag}</p>\n</div>\n<div class='single-lyric'>\n{content}</div>\n"
- output_spar = ''.join("<p class='ver-%d'>%s</p>\n" % (c[0], c[1]) for c in enumerate(dcontent, 1))
- output_section += item_div.format(timetag=re.sub('[\[\]]', ' - ', dtimetag), content=output_spar) + '</div>'
- elif self.format == 'txt':
- for item in dparallels:
- dtimetag = item[0]
- dcontent = item[1::]
- item_div = "{timetag}\n{content}\n"
- output_spar = ''.join("%s\n" % c[1] for c in enumerate(dcontent))
- output_section += item_div.format(timetag=re.sub('[\[\]]', ' - ', dtimetag), content=output_spar)
- return output_section
-
- def doconv(self, sections):
- last_album = ''
- output = ''
- for item in sections:
- header = item['name']
- album = item['album']
- artists = ','.join(item['artists'])
- a = item['lyric']
- if a is not None:
- ly_res = {}
- lyrics = [a['0'], a['1'], a['2']]
- if self.ts == 'parallel':
- ly_res = self.parallel(lyrics)
- elif self.ts == 'chunk':
- ly_res = self.chunk(lyrics)
- if self.format == 'html':
- if last_album != album:
- last_album = album
- output += '<h1>%s</h1>' % album
- output += Lyric2Book.html_template % {'header': header, 'album': album, 'artists': artists, 'lyrics': ly_res}
- elif self.format == 'txt':
- if last_album != album:
- last_album = album
- output += album + '\n\n'
- output += Lyric2Book.txt_template % {'header': header, 'album': album, 'artists': artists, 'lyrics': ly_res}
- self.res = output
-
- def output(self):
- filename = self.title + '.' + self.format
- with open(filename, 'w+', encoding='utf-8') as f:
- res = self.res
- if self.format == 'html':
- res = Lyric2Book.html_frame % (self.title, res)
- elif self.format == 'txt':
- res = Lyric2Book.txt_frame % (self.title, res)
- f.write(res)
-
-
- if __name__ == '__main__':
- with open('bbc.txt', 'r', encoding='utf-8') as file:
- t = Lyric2Book(file_format='thjxt', title='BBC Documentary', typesetting='parallel')
- content = json.loads(file.read())
- t.doconv(content['result'])
- t.output()
Feb. 6, 2019
2019年的春节只有5天,二十八放假,初三上课。
放假前几分钟,我在想我能够做什么做什么,把计划中的事,未做完的事,未计划的事统统完成,大部分都是课外的事。
我确实完成了一些,但有些我却总也走不下去。歌词工具从十月份开始有想法,十一月份真正开始,到现在有三四个月了。借着这个想法我才真正熟悉了Python,后台逻辑其实一个月以前就结束了,一些改进的想法也决定搁置,没有再重构;前端最关键的部分也测试证明可行,然后我就不走了。
More...