……一篇篇写是不可能的……看完也是不可能的…… 只能隔几节水一水的样子~
数据通路
第一次看到这个词,我会以为它是用来传输数据的,然而他的定义是:
一个用来操作或保存处理器中数据的单元。在MIPS实现中,数据通路部件包括指令存储器,数据存储器,寄存器堆,ALU和加法器。
另外,之前在跳转指令中经常看到的程序计数器:
程序计数器(Program Counter)存放下一条将要被执行的指令的地址存储器
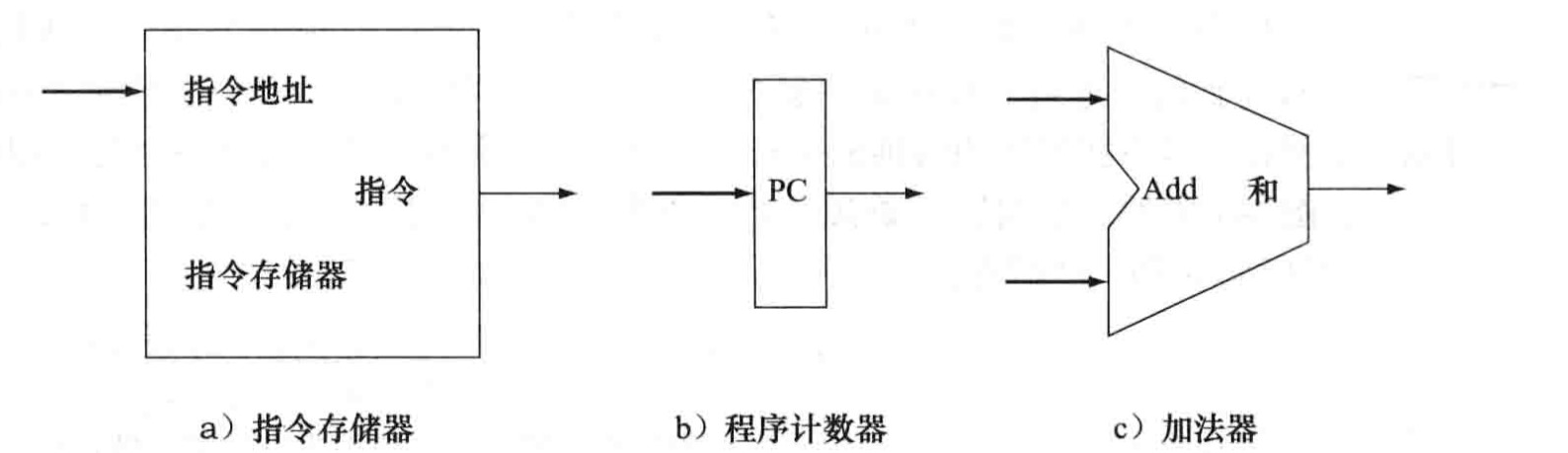 这是存取指令需要的两个状态单元,以及计算系一条指令地址所需要的加法器
这是存取指令需要的两个状态单元,以及计算系一条指令地址所需要的加法器
其中,a)指令存储器是只读的(不考虑装载指令的过程),一个地址对应一条指令,所以把他看作组合逻辑也没有什么问题。任意时刻的输出都反映了输入地址处的内容,而不需要都控制信号;b)程序计数器(PC),实际上是一个32位的寄存器,程序计数器在每个时钟周期末都会被写入,所以不需要写控制信号;c) 加法器,将ALU设定为加法,用来自增PC、计算绝对地址
R型指令
R型指令(算术逻辑指令) add sub AND OR slt R型指令的格式如下:
| op | rs | tr | td | shamt | funt |
|---|---|---|---|---|---|
| 6位 | 5位 | 5位 | 5位 | 5位 | 6位 |
- rs:目的寄存器
- rt,rd:源寄存器
寄存器堆:包含一系列寄存器的状态单元,可以通过提供寄存器号进行读写
- 读出(2个)(每个数据字需要寄存器堆有一个输入,一个输出)
- 数据字1
- 数据字2
- 写入(1个)(每个寄存器字需要有两个输入:寄存器号和要写的数据)
综上,寄存器堆一共有4个输入(三个寄存器号和1个数据)和两个输出(两个数据)。
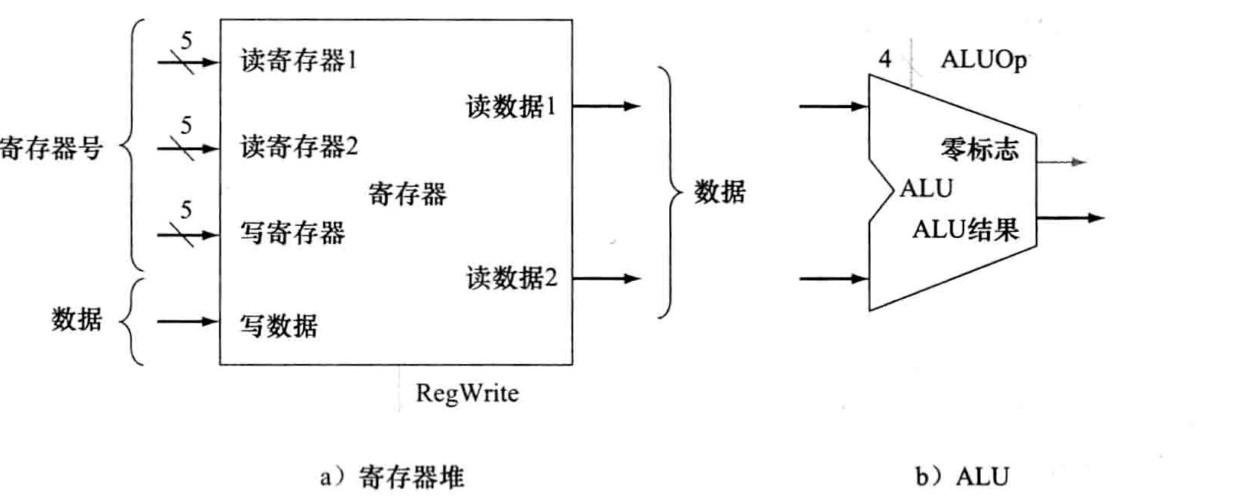 ALUOP:4位ALU操作信号。
ALUOP:4位ALU操作信号。
可以在同一时钟周期内读出和写入同一寄存器。读操作将读出以前写入的内容;写入的内容在下一周期才可读。
存取指令
MIPS存取指令的一般形式:lw $t1, offset_value($t2)(取数)或sw $t1, offset_value($t2)(存数)
在这类指令中,通过将基址寄存器$t2的内容与指令的16位带符号偏移地址相加,得到存储器地址
还需要一个单元将16位的偏移地址符号扩展(signed-extend)位32位的带符号值,以及一个保存读出或写入数据的存储单元。
符号扩展:为增加数据项的长度,将原有数据项的最好为复制到新数据项多出来的高位。 简单来说,就是增大数字存储的位数(十六位变32位)同时不改变原值的方法 例如这是个8位扩展为16位的例子(二进制表示)________10101000 1111111110101000
数据存储单元在存储指令时被写入,所以他有读写控制信号、地址输入和写入存储器的数据输入。 虽然数据存储器的读、写控制信号都是独立的,但是任意时钟只能激活其中一个。标准的存储芯片实际上有一个写使能(enable)信号用于写操作。
跳转指令
跳转指令将偏移地址的低26位左移两位,一直代替PC的低28位。 移位通过给偏移量后面加上两个0实现。
beq指令(相等则分支)
beq $t1, $t2, offset,若$t1和$t2的值相等,则跳转到offset
offset是一个16位偏移量。
分支目标地址(branch target address) = PC值 + 符号扩展后的指令偏移量字段
注意:
- 基地址是分支指令的下一条指令的地址(PC + 4)
- 系统结构规定偏移量左移两位以指示字为单位的偏移量(按字节寻址)
当分支条件为真,分支目标地址成为新PC,称为分支发生(branch taken); 否则 自增后的PC取代当前PC,称为分支未发生(branch not taken)。
分支数据通路需要两个步骤:
- 计算分支目标地址
- 比较操作数(将ALU设为减,检测结果是否为零(可以检测ALU的零信号))
在实际的MIPS指令集中,分支指令是延迟的,无论分支条件是否满足,她之后的耐滔指令总被执行。条件不满足时,情况不变,条件满足时,延迟的分支指令先执行它下面的的那条指令,然后再跳转到指定的目标地址。 这个是为了照顾流水线而设计的,具体不用考虑。

